Case Study: An AI Sales Operator Agent for Drinks Ghana eCommerce
An AI sales agent in production for Drinks Ghana — taking wholesale orders across web chat, WhatsApp, and Instagram DM against a live Odoo catalog. 824 sessions, ~6-second median reply, 1.7% escalation rate, and a channel split that surprised the team: web users browse; messaging users buy.
Client: ATI Drinks Ghana — wholesale beverage operations, Accra Surfaces: Website chat widget, WhatsApp, Instagram DM Stack: Odoo Online Enterprise, Flutterwave, Meta Cloud API (WhatsApp + Instagram), Supabase, Node.js / TypeScript, OpenAI Role: Technical architect - XpertLabs.io Scope: Sales agent that takes orders against the live Odoo catalog across three channels and escalates when the work needs human judgment.
Result so far
In the first month in production, the assistant handled 824 customer sessions, replied in a median of about six seconds, escalated only 1.7% of sessions to a human, and surfaced a channel pattern Drinks Ghana could act on: web users browse; WhatsApp and Instagram users buy.
The brief
Drinks Ghana was losing orders. Wholesale customers in Accra place bulk beverage orders late at night, while comparing two competitors at once, through whichever surface they already use — the website, WhatsApp, or Instagram. The operations team caught what it could on shift. The rest — overnight orders, the ones lost while a buyer waited for a faster reply — disappeared, and the buyers that would prefer chat to filling heavy checkout forms.
The wholesale ground was there before any AI. Odoo Online Enterprise held the catalog, prices, stock, customers, and order records. Flutterwave was wired into the Odoo checkout flow for Ghana cedis. Yango was the default last-mile inside Accra for small-basket orders. The team was already taking orders by phone, WhatsApp, and Instagram on shift — the system just needed to extend that coverage to the hours and channels the team could not.
The agent had to match that operating reality exactly. Not invent a new catalog system. Not introduce a new payment rail. Not retrain the operations team to work in a surface different from the one Odoo was already producing receipts in. The brief, in operating terms, was to pick up the conversations the team could not pick up in the moment — and to do so without telling the customer anything the warehouse would not honor.
This is the case file for how it was built, and what each operating decision answered.
Decision 1: Two prompts, not one
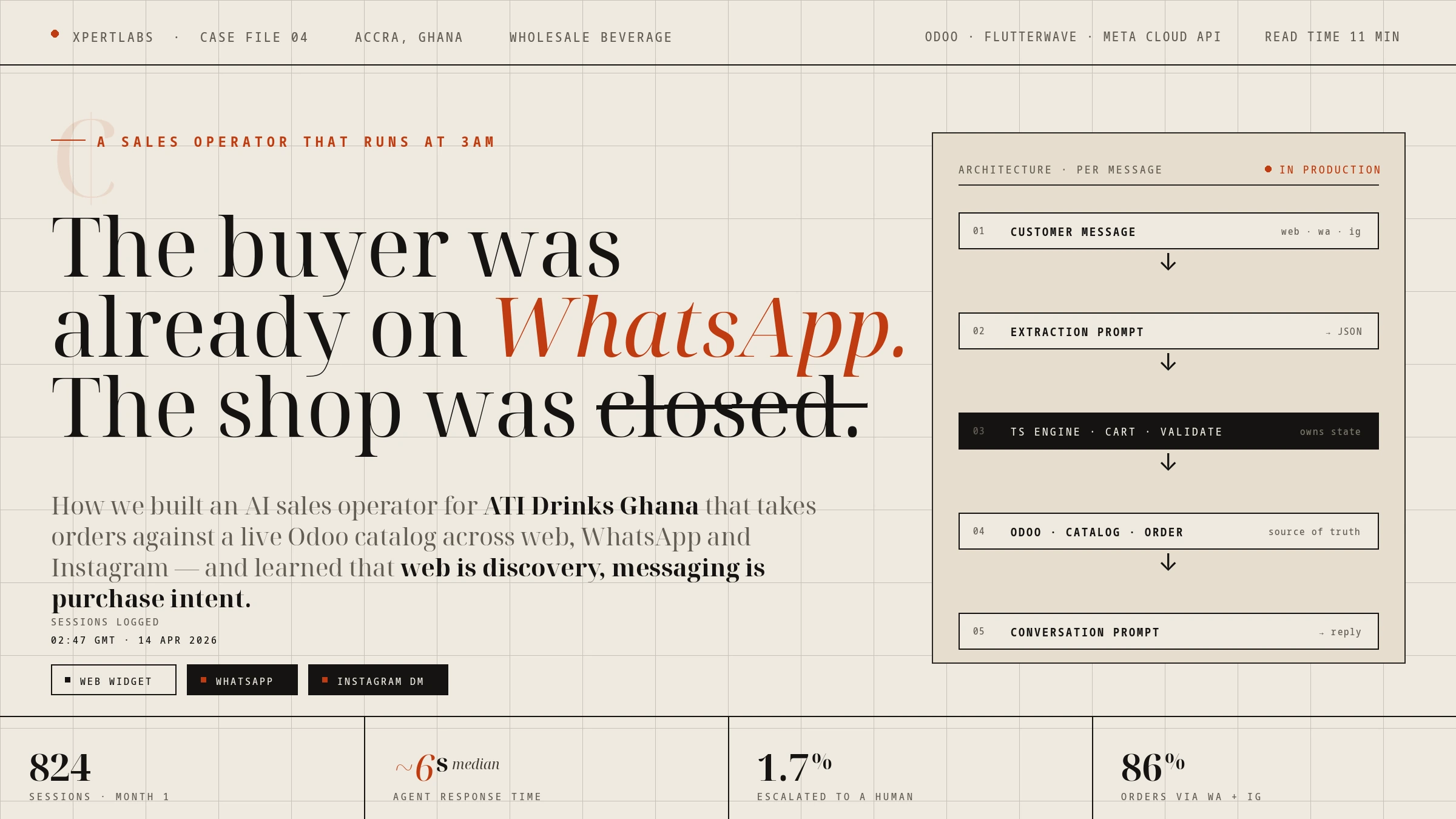
The first architectural decision was to split the model call into two prompts running in sequence per customer message:
Customer message → extraction prompt → TypeScript engine (cart + validation) → Odoo (catalog + order) → conversation prompt → customer reply
The extraction prompt takes the customer's message plus a compact session context and returns structured JSON: intent, products mentioned, quantities, back-references like "yes, two of those," sentiment, and any removal requests against the cart. Nothing in the extraction output is prose; it is data the engine can validate.
The conversation prompt takes the validated extraction output, the current cart state, the order-flow stage, and the relevant catalog facts, and writes the reply the customer reads.
The split paid for itself three ways. First, the extraction prompt is small and fast and runs against a cheaper model class than the conversation prompt; the cost per message stays inside what wholesale margins can absorb at volume. Second, the cart stops hallucinating. When a single prompt is asked to parse the customer's message and compose the reply at the same time, it occasionally invents a product line that does not exist in the Odoo catalog. Splitting the jobs lets the TypeScript engine validate every product the extraction prompt names against the live catalog before the conversation prompt sees it. Phantom products do not survive the round trip. Third, the engine in the middle — not the model — owns the cart, the back-reference resolver, the stage logic, and the delivery rules. That boundary is what makes the system safe to run unsupervised.
The model never holds the cart state; the engine does.
Decision 2: Odoo as the system of record
The agent reads Odoo at every turn that requires catalog truth. Cart drafts live in Supabase along with sessions, messages, and checkout state, but the moment a customer confirms an order the engine writes the sale order to Odoo and hands the customer a Flutterwave checkout link generated from the Odoo flow.
The alternative would have been to build a parallel catalog inside the assistant's database, sync it from Odoo on a schedule, and let the agent quote prices out of that mirror. That design is faster on the read path. It also drifts. The warehouse takes a stockout in the morning, Odoo updates, the mirror lags, and by afternoon the assistant is selling a product the warehouse cannot ship. Drift between the system the operations team uses and the system the customer-facing assistant uses is the failure mode that turns AI sales into customer service work the operator now has to clean up.
The simpler discipline is to pay the read latency and quote against Odoo directly. Sessions and messages live in Supabase because they are conversation state, not commerce truth. Odoo holds the receipts. The split is precise about which system owns which kind of fact.
Decision 3: Three channels, three platform realities
The same agent runs across the website chat widget, WhatsApp, and Instagram DM. Each surface has its own platform reality, and each one drove a specific implementation detail.
The chat widget is embedded on the Odoo Online website. Odoo Online is hardened, so the widget had to fit inside the website's Content Security Policy — a small iframe posting customer messages to the assistant's API. The location-picker flow runs in a separate page so it can request geolocation outside the in-app webview restrictions that Instagram, Facebook, and Messenger browsers all impose.
WhatsApp uses the Meta Cloud API. The token has a sixty-day window. The obvious refresh strategy is a setInterval running every fifty days, which fails silently because Node clamps any setInterval above roughly twenty-five days to one millisecond. The system uses a daily-check pattern instead: every twenty-four hours, the worker reads the token's stored issuance date and refreshes if it is older than fifty days. The Instagram token follows the same pattern.
Instagram DM uses the Meta Messenger API surface, which introduced two operational constraints. First, when an operator replies to an Instagram conversation, the API expects an Instagram-scoped identifier, not the WhatsApp identifier. Mixing those silently routes the reply to the wrong place. Second, Instagram conversations expect Ice Breakers — the suggested-message prompts that appear when a customer opens a fresh DM. The system auto-provisions Ice Breakers at server startup so they stay aligned with whatever the current product menu and welcome flow demand. A one-shot script handles the same provisioning when the menu changes outside a server restart.
Decision 4: Delivery rules encoded, not inferred
Delivery decisions are not a model job. The agent is not allowed to reason its way to a delivery quote from first principles, because a model that drafts a quote from inferred logic invents prices, mixes up regions, and produces a customer-service ticket the operations team then has to fix.
The rules live in code:
- Accra orders under GH₵10,000 — Yango delivery, free for the customer (ATI subsidizes the Yango fee).
- Accra orders at or above GH₵10,000 — ATI's own fleet delivers, GH₵50 fee.
- Outside Accra — the assistant escalates to a human, because outside-Accra logistics depend on freight partner availability, customer pickup preferences, and pre-payment status the assistant should not adjudicate alone.
The conversation prompt receives the delivery rule applicable to the current cart as a fact, not a question. The assistant tells the customer what the delivery will be; it does not invent the delivery and then commit the operations team to the invention.
Decision 5: What runs at 3am
The system's job is to run when the builder is not in the room. Drinks Ghana's wholesale customers place orders late, and the assistant takes orders overnight without supervision.
Token refresh runs on the daily-check pattern across both Meta APIs. Ice Breakers auto-provision on server startup. The agent console — the interface human operators use to pick up escalations — keeps operators signed in long enough that a handoff at 02:00 does not require an authentication dance the operator did not need at 14:00. When an Instagram conversation escalates past the assistant's competence, the routing carries the Instagram identifier intact so the operator's reply lands in the conversation the customer started, on the platform the customer started it on. When a welcome-menu tap nudges the system to bypass the standard greeting and jump straight to the customer's intent, the system honors the tap rather than re-running the greeting and losing the moment.
A system that requires a person at 3am to keep operating is not a system; it is a person doing the work in the wrong place. The architecture pushes the human to where their judgment is the load-bearing input — escalations, exceptions, outside-Accra logistics, anything that needs the operations team's discretion — and keeps the assistant inside its competence everywhere else.
Where it stands
The system has been live in production with real customers for a little under a month at the time of writing. Order volume is still early, so we are not treating order-side percentages as settled results yet. Those figures will be added once the base is large enough.
The operating data is already useful:
Channel use and order placement are inverted. 96.5% of customer sessions come in through the website chat widget. 86% of confirmed orders come in through WhatsApp and Instagram.
This changed how we think about each channel: web is discovery; messaging is purchase intent. The architectural decision to treat each surface as its own platform reality pays off in the order data, not just the technical integration.
Median agent response time is about six seconds, p90 around nine seconds, across 329 customer-to-assistant message pairs in 824 sessions. The two-prompt architecture absorbs the cost of the extraction round-trip without surfacing latency to the customer.
Roughly 1.7% of sessions escalate to a human oxperator — 14 handoffs across 824 sessions. The vast majority of conversations resolve inside the agent's competence; the small minority that cross it get a person.
What the case demonstrates
Software built from outside an operating ground has to invent what the operator already knows: the currency, the delivery rules, the channels customers actually use, the difference between Instagram and WhatsApp identifiers, the twenty-five-day setInterval ceiling in Node, the way Odoo's checkout flows interact with Flutterwave for Ghana cedis.
This is the pattern XpertLabs builds for: AI systems that do not replace the operating ground, but encode it.
Build from inside the problem. Encode the operating rules.
Let the system run when the builder is not in the room.
Stay in the loop
New posts, straight to your inbox
Engineering lessons, case breakdowns, and thinking from the team that builds. No spam — unsubscribe any time.